Simplifying Databases: The Power of Data Abstraction and Essential Abstractions
Unveiling the Hidden Layers: Demystifying Data Abstraction in Databases for Optimal Performance and User Experience


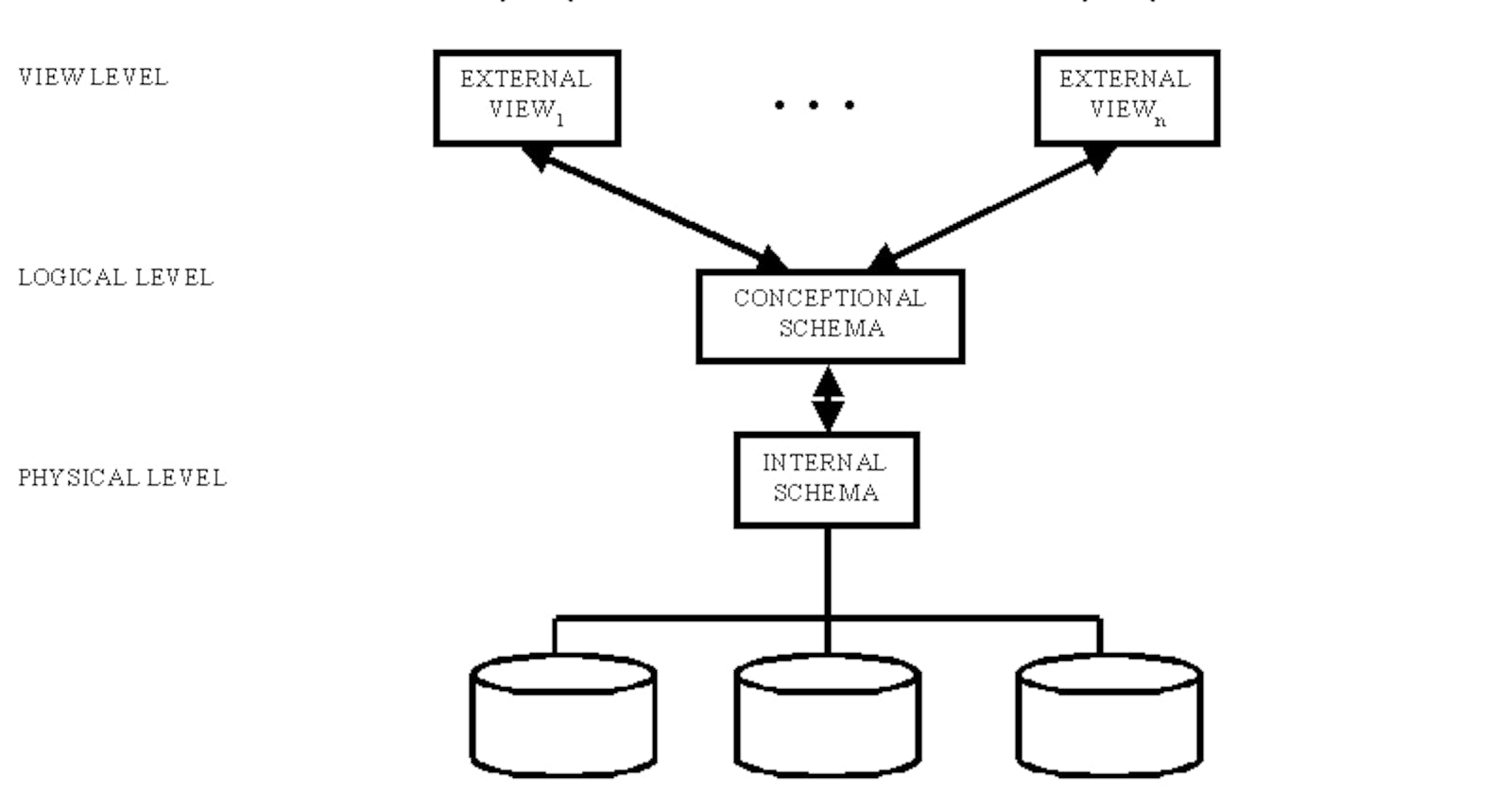
Table of contents


No headings in the article.
Database systems use abstraction to simplify database design and improve efficiency in terms of data retrieval and user usability. There are three levels of data abstraction: physical, logical, and view.
Physical Level: This is the lowest level of data abstraction and deals with how data is stored in memory. It involves access methods (sequential or random) and file organization methods (e.g., B+ trees or hashing). Details such as storage blocks and memory usage are hidden from the user. For example, when storing employee details, the specifics of storage and memory are kept hidden.
Logical Level(Conceptual): This level represents the actual data stored in the database in the form of tables and defines the relationships between data entities. It provides a relatively simple structure for storing information. The information available at the view level is unknown at this level. Attributes of an employee and relationships (e.g., with the manager) can be stored at the logical level.
View Level: This is the highest level of abstraction, which allows users to interact with the database by viewing a specific part of it. Users can access data in the form of rows and columns using tables and relations. Multiple views of the same database may exist. The view level exists to make the database easily accessible to individual users, hiding storage and implementation details.
The main purpose of data abstraction is to achieve data independence, which saves time and costs when modifying or altering the database. Data independence allows changes to be made at one level of the system without affecting the schema at the next level. There are two types of data independence:
Physical Level Data Independence: This refers to the ability to modify the physical schema without affecting the conceptual or logical schema. It allows optimization changes, such as using new storage devices, modifying data structures, altering indexes, or changing file organization techniques.
Logical Level Data Independence: This refers to the ability to modify the logical schema without affecting the external schema or application programs. Changes can include inserting or deleting attributes, altering table structures, or modifying entities and relationships in the logical schema.
By providing data independence, database systems allow for flexibility and easier maintenance as different levels of the system can be modified independently.